
대감집
[Risk Hedging] 시장 별 관계성 분석 본문
- 포트폴리오 전략 구성 시 다양한 종목이 분포하는 것이 헷징을 위해서 현명하다
- 전략 구성을 위해서 각 시장에 대해서 분석을 진행한다
- S&P500 Sector 별 시장이 헷징을 하기에 가장 적합한 것으로 판단된다
- 가상화폐 시장은 오를때 같이 오르고 내릴때 같이 내리는 경향을 가짐
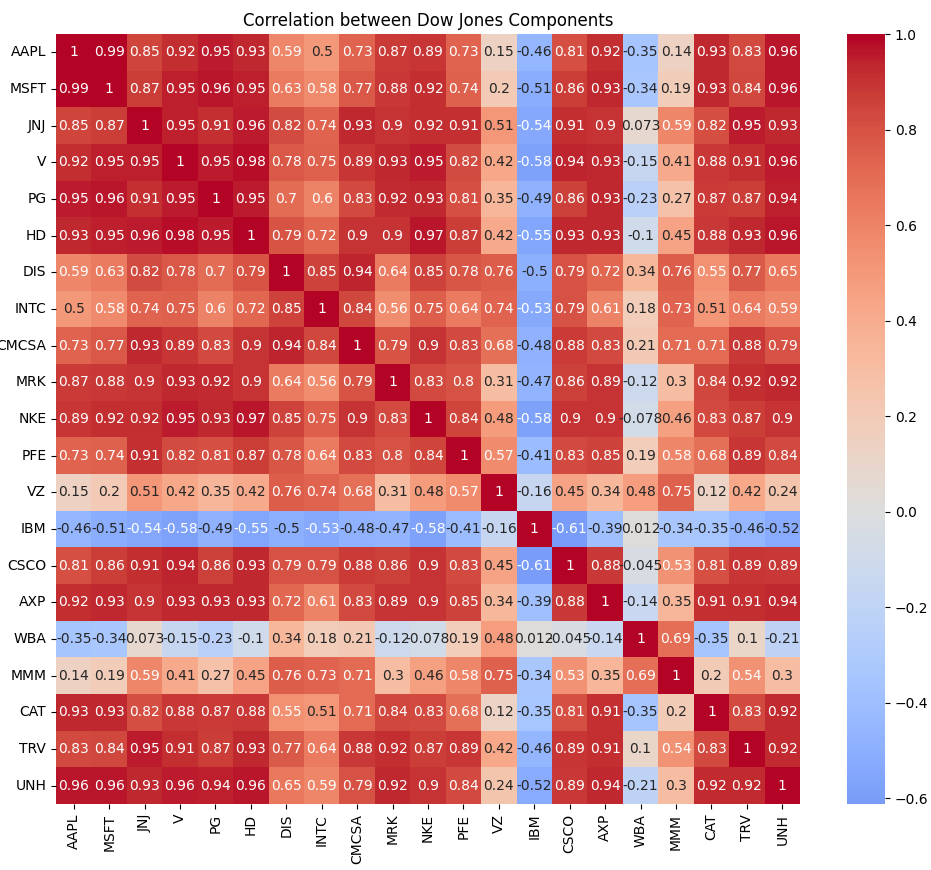
- Dow-jones 또한 대부분 비슷한 경향 을 보임
- S&P500에서 Sector가 다를 때 서로 다른 경향을 보임
- 가상화폐 시장

- Dow-Jones 시장
- S&P500 Sector 별 시장

import yfinance as yf
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 암호화폐 목록
cryptos = {
'Bitcoin': 'BTC-USD',
'Ethereum': 'ETH-USD',
'Binance Coin': 'BNB-USD',
'Cardano': 'ADA-USD',
'Solana': 'SOL-USD',
'Ripple': 'XRP-USD',
'Polkadot': 'DOT-USD',
'Dogecoin': 'DOGE-USD',
'Litecoin': 'LTC-USD',
}
# 데이터 다운로드 함수
def get_crypto_data(cryptos):
data = {}
for name, ticker in cryptos.items():
crypto_data = yf.download(ticker, start='2019-09-01', end='2024-09-01')['Close']
data[name] = crypto_data
return pd.DataFrame(data)
# 암호화폐 데이터 가져오기
crypto_data = get_crypto_data(cryptos)
# 상관관계 분석
correlation_matrix = crypto_data.corr()
# 상관관계 시각화
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('Correlation between Different Cryptocurrencies')
plt.show()
# 상관관계 출력
sorted_correlations = correlation_matrix.unstack().sort_values(ascending=False)
sorted_correlations = sorted_correlations[sorted_correlations < 1] # 자기 상관관계 제외
print("Sorted Correlations:\n", sorted_correlations)import yfinance as yf
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 다우존스 구성 종목 리스트
dow_tickers = [
'AAPL', # Apple Inc.
'MSFT', # Microsoft Corp.
'JNJ', # Johnson & Johnson
'V', # Visa Inc.
'PG', # Procter & Gamble
'HD', # Home Depot
'DIS', # Walt Disney
'INTC', # Intel Corp.
'CMCSA', # Comcast Corp.
'MRK', # Merck & Co.
'NKE', # Nike Inc.
'PFE', # Pfizer Inc.
'VZ', # Verizon Communications
'IBM', # International Business Machines
'CSCO', # Cisco Systems
'AXP', # American Express
'WBA', # Walgreens Boots Alliance
'MMM', # 3M Company
'CAT', # Caterpillar Inc.
'TRV', # Travelers Companies
'UNH' # UnitedHealth Group
]
# 데이터 다운로드 함수
def get_dow_data(tickers):
data = {}
for ticker in tickers:
stock_data = yf.download(ticker, start='2010-01-01', end='2024-01-01')['Close']
data[ticker] = stock_data
return pd.DataFrame(data)
# 다우존스 데이터 가져오기
dow_data = get_dow_data(dow_tickers)
# 상관관계 분석
correlation_matrix = dow_data.corr()
# 상관관계 시각화
plt.figure(figsize=(12, 10))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('Correlation between Dow Jones Components')
plt.show()
# 상관관계 출력
sorted_correlations = correlation_matrix.unstack().sort_values(ascending=False)
sorted_correlations = sorted_correlations[sorted_correlations < 1] # 자기 상관관계 제외
print("Sorted Correlations:\n", sorted_correlations)import yfinance as yf
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 섹터별 주요 종목 설정 (META로 변경)
tickers = {
'Information Technology': ['AAPL', 'MSFT', 'NVDA', 'GOOGL', 'ADBE'],
'Health Care': ['JNJ', 'UNH', 'PFE', 'MRK', 'ABBV'],
'Financials': ['JPM', 'BAC', 'WFC', 'C', 'GS'],
'Consumer Discretionary': ['AMZN', 'TSLA', 'DIS', 'NFLX', 'CMCSA'],
'Consumer Staples': ['PG', 'KO', 'PEP', 'WMT', 'MDLZ'],
'Energy': ['XOM', 'CVX', 'SLB', 'COP', 'OXY'],
'Industrials': ['BA', 'CAT', 'HON', 'MMM', 'GE'],
'Materials': ['LIN', 'NEM', 'VMC', 'FCX', 'APD'],
'Communication Services': ['T', 'VZ', 'NFLX', 'GOOGL', 'META'], # FB -> META로 변경
'Utilities': ['NEE', 'DUK', 'SO', 'EXC', 'SRE'],
'Real Estate': ['AMT', 'PLD', 'CZR', 'SPG', 'VTR'],
'Telecommunications': ['T', 'VZ', 'TMUS'],
'Consumer Services': ['DIS', 'NFLX', 'CMCSA', 'T', 'VZ'],
'Transportation': ['UPS', 'FDX', 'LUV', 'DAL', 'AAL'],
'Retail': ['AMZN', 'WMT', 'COST', 'TGT', 'TJX'],
}
# 데이터 다운로드 함수
def get_data(tickers):
data = {}
for ticker in tickers:
stock_data = yf.download(ticker, start='2010-01-01', end='2024-01-01')['Close']
data[ticker] = stock_data
return pd.DataFrame(data)
# 데이터 가져오기
data = get_data([ticker for sector in tickers.values() for ticker in sector])
# 상관관계 분석
correlation_matrix = data.corr()
# 상관관계 시각화
plt.figure(figsize=(14, 12))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', center=0)
plt.title('Correlation between Different Stocks in S&P 500 Sectors')
plt.show()
# 상관관계 출력
sorted_correlations = correlation_matrix.unstack().sort_values(ascending=False)
sorted_correlations = sorted_correlations[sorted_correlations < 1] # 자기 상관관계 제외
print("Sorted Correlations:\n", sorted_correlations)'투자 분석' 카테고리의 다른 글
| [Turnaround] 전략 (3) | 2024.10.28 |
|---|---|
| [재무제표] 손익계산서 분석 (5) | 2024.10.05 |
| [시장 지표] 상관관계 분석 (3) | 2024.09.20 |
| [돌파매매] 투자 전략 검증 (0) | 2024.09.20 |
| [모멘텀] 투자 전략 검증 (0) | 2024.09.20 |
'투자 분석' Related Articles
more


